What I Bought — The Environment on Day 1
Why this first: I want a place to point back to as I migrate the stack to something more reliable and affordable.
The gist: I first saw Hacker News Books for sale on Flippa. The web app parses all the comments each week from HackerNews to see what books are being discussed. It then compiles the top books discussed and updates the website and sends a weekly newsletter. The main problem is the site was 8 years old and had minimal improvements.
HNB Diagram:
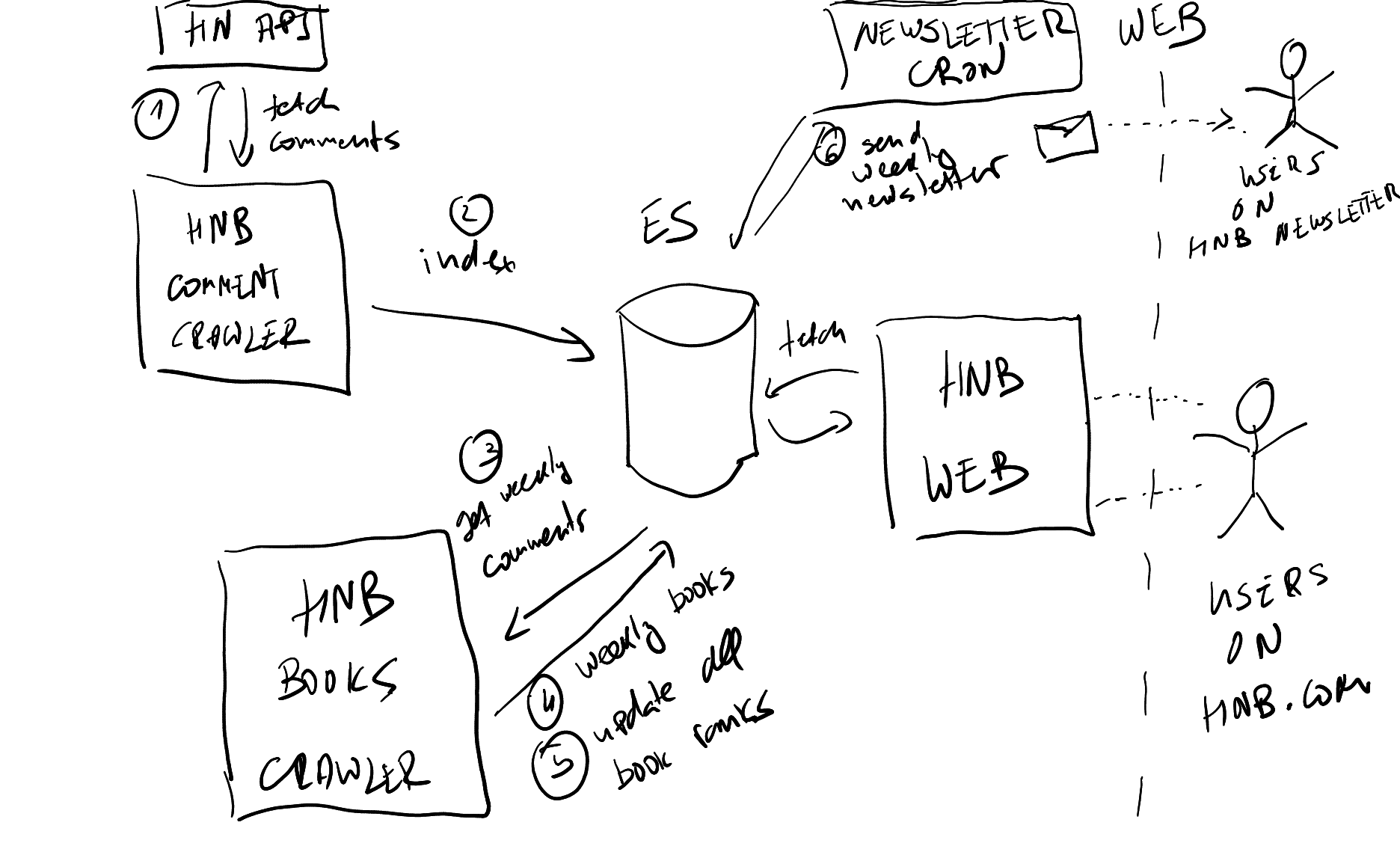
Stack (inherited)
- Core store: Elasticsearch 1.x (single cluster; books, comments, rankings, scores)
- App/runtime: Python 2; cache: Redis
- Infra: EC2 + ECS, images in ECR; storage/backups in S3; DNS: Cloudflare
- Ops: Lambda scheduled a nightly restart of the web stack
Inherited release / rollout pattern (how changes went live)
- Trigger: [what kicked off a deploy—manual push / cron / “when I SSH’d”]
- Packaging: [docker image / git pull]
- Health checks: [none / basic LB ping / app endpoint?]
- Fallback: [nightly reboot / manual rollback notes / restore from snapshot]
Goal later: move from scheduled restarts to automated, health-based recovery (industry guidance prefers healing over rebooting).
Inherited toil (the repetitive work I saw)
- Nightly reboot to “stabilize” the app/services
- One-off fixes deployed outside a release cadence
- Manual cache invalidation / reindex steps after certain changes
- Ad-hoc snapshot checks (no automated verification)
- Chasing mapping/type drift in ES when adding fields
“Toil” = manual, repetitive, automatable work that provides no lasting value and grows with the service—prime candidate to eliminate.
Risks I noted right away
- End-of-life runtime (Python 2), aging search stack (ES 1.x)
- Reliability via reboot instead of health-based recovery
- Single cluster as source of truth
What I’ll tackle first
- Search migration journal: ES 1.x → 2.x → 5.x (queries, mappings, scripts, reindex)
- Reduce toil: replace nightly reboot with automated recovery; capture changes in a small changelog (Added/Changed/Fixed) for each week.
Ownership handoff (day-1 checklist)
- Access: AWS, Cloudflare, ECR/ECS, S3, ES cluster, newsletter tool
- Backups: last ES snapshot date, how to restore (one line)
- Secrets: where env vars live; rotation status
- Deploy trigger: who/what pushes to prod
- “Break glass”: how I’d roll back if deploy goes sideways